
PIM provides a novel approach of energy efficiency to computing. It attempts to lower the critical path for loading/storing data to/from memory by placing compute close to memory. As large cloud centers and HPC systems require an increasing amount of energy, the reduction of energy usage within our clusters is important.
UPMEM provides the first publicly available, open-source, general-purpose PIM architecture. Given the restrictive access of other architectures, we have focused our efforts on UPMEM PIM. This solution is a drop-in DDR4 DIMM replacement. Each DIMM consists of 128 DIMM Processing Units (DPUs) that are capable of 24 hardware threads with a 14-stage pipeline. A 40 rank single socket server is capable of 2560 DPUs (64 DPUs per rank). The UPMEM PIM architecture is shown below1.
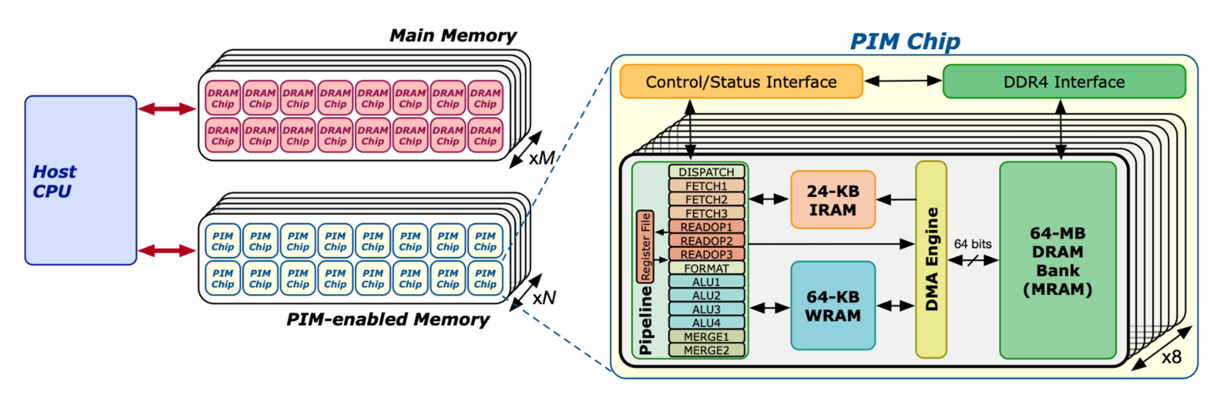
The host has direct access to the DPUs main RAM (MRAM) through a standard DDR4 interface. Calls within the UPMEM API will orchestrate device and host data movements. Additionally, the device kernel coordinates movement to/from the MRAM to the working RAM (WRAM). The WRAM is a working set cache necessary to perform instructions within the 14-stage pipeline.
Due to a lack of power and area on the UPMEM PIM DIMM , there are two main bottlenecks that exist on this PIM architecture. Firstly, there is no floating-point (fp) unit. All fp32 and fp64 instructions are emulated through int32 instructions. To address this limitation, there have been several attempts to speed up fp performance using look-up tables. Secondly, there is a lack of an inter-dpu cross-bar network. We focus on addressing this limitation within this work through a software runtime programming system.
The Legion programming system is a task-based scheduler for distributed heterogeneous systems. Legion issues necessary data-movement operations by the automatic generation of application task graphs through user-defined coherence privileges. Additionally, this implicitly provides 1) asynchronous execution of independent tasks and 2) sub-division of tasks into available independent architecture resources.
Achieving high performance requires the programming system to understand the structure of program data to facilitate efficient placement and movement of data.
As mentioned in above, UPMEM PIM has a lack of a cross-bar communication network across processors. The goal of using a task-based runtime is to hide these large latencies. We use Legion to facilitate this severe bottleneck. Due to the implicit parallelism that Legion provides through its data structure abstractions, Legion can create a high degree of concurrent tasks.
Legion supports heterogeneous devices through a module system within Realm. We implement the notion of an UPMEM module and support it through the rest of the Legion stack. In order to make use of the module, the programmer will define a processor constraint DPU_PROC for the task.
Each DPU presents itself as a processor within the Legion runtime. The MRAM is managed by Legion to send/receive data from the host/device. The runtime has the ability to asynchronously launch kernels. Blocking operations are synchronized through a registered callback interface.
On the device side, the standard UPMEM device programming model is used with modifications to data access. DPU kernels use Legion notions of the index space abstraction. This includes access to iterators, read operators, and write operators.
Image from ETH SAFARI Lab↩︎